
Pythonで選挙データを分析してみよう!③〜埼玉投票結果 選挙区情報 読み込み編〜
このシリーズでは、2025/07/21に行われた参院選挙結果を分析するためのプログラムを、一つずつ紐解いて解説していきます。
いよいよ第3弾です。 これまでは不要な行や列を「掃除」するのがメインでしたが、今回はデータの構造自体を分析しやすい形に「変形」させるという、一歩進んだテクニックに挑戦します。
作成したコードは Github に公開しているので、興味があれば、見てみてください。
※コードは、予告なく、改変/削除されることがあります。
扱うスクリプトは cleanup_voting_result_by_electoral_district.py です。今回もデータは手ごわいです!
今回のファイルは、複数のシートがあります。
今回の敵は、最強の「横長データ」
まずは、今回相手にするExcelデータを見てみましょう。これは、「候補者別市区町村別得票調べ」というシートです。
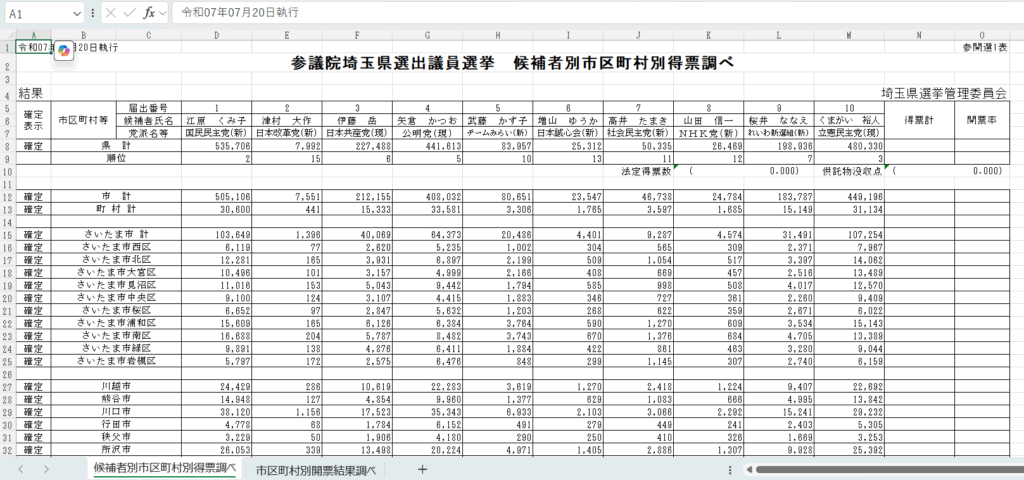
プログラムで読み込むとこんな感じです。
"確定\r\n表示",市区町村等,届出番号,1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0,10.0,得票計,開票率
,,候補者氏名,江原 くみ子,津村 大作,伊藤 岳,矢倉 かつお,武藤 かず子,増山 ゆうか,高井 たまき,山田 信一,桜井 ななえ,くまがい 裕人,,
,,党派名等,国民民主党(新),日本改革党(新),日本共産党(現),公明党(現),チームみらい(新),日本誠心会(新),社会民主党(新),NHK党(新),れいわ新選組(新),立憲民主党(現),,
確定,県 計,,535706.0,7992.0,227488.0,441613.0,83957.0,25312.0,50335.0,26469.0,198936.0,480330....
確定,さいたま市西区,,10330.0,211.0,4918.0,8623.0,2038.0,601.0,1073.0,621.0,4537.0,9851.0,42803.0,100.0
...
(中略)
...
"確定\r\n表示",市区町村等,届出番号,11.0,12.0,13.0,14.0,15.0,得票計,開票率,,,,,
,,候補者氏名,りゅうの まゆみ,古川 俊治,大津 力,斉藤 よしひで,石濱 哲信,,,,,,
,,党派名等,日本維新の会(新),自由民主党(現),参政党(新),無所属(新),日本保守党(新),,,,,,,
確定,県 計,,233333.0,593673.0,157937.0,13169.0,2087.0,3485290.0,100.0,,,,,
確定,さいたま市西区,,5021.0,12177.0,3799.0,325.0,87.0,42803.0,100.0,,,,,見ての通り、これまでで最も複雑な構造をしています。
- 横に長い:候補者名が列になっており、右にずらーっと並んでいます。これを「横長なデータ」や「ワイドフォーマット」と呼びます。
- データが分断されている:なんと、全15名の候補者が1つの表に収まらず、シートの途中で2つの表に分断されています。
- 情報がてんこ盛り:ヘッダーが複数行あり、党派名なども含まれています。
このままでは、「A候補者の合計得票数は?」とか「B党の候補者の得票数を市町村ごとに比較したい」といった分析が非常にやりにくい状態です。
目指すは「縦長データ(Tidy Data)」への変身
そこで、この「横長データ」を、プログラムで扱いやすい「縦長データ(ロングフォーマットやTidy Dataとも呼ばれます)」に変形させます。目指すゴールはこんな形です。
| 市区町村名 | 候補者名 | 党派名等 | 得票数 |
|---|---|---|---|
| さいたま市西区 | 江原 くみ子 | 国民民主党(新) | 10330 |
| さいたま市西区 | 津村 大作 | 日本改革党(新) | 211 |
| さいたま市西区 | 伊藤 岳 | 日本共産党(現) | 4918 |
| … | … | … | … |
| さいたま市西区 | りゅうの まゆみ | 日本維新の会(新) | 5021 |
| … | … | … | … |
1行に「どの市区町村」で「誰が」「何票とったか」という情報がまとまっており、非常にスッキリしましたね。これなら集計やグラフ化も簡単です。
いざ、データ大手術!
この変形を実現するための、スクリプトの核心部分を見ていきましょう。
Step 1: 候補者リストという「正解」を先に作る
これだけ複雑なフォーマットだと、プログラムに候補者名を自動で正しく認識させるのは至難の業です。そこで、発想を転換します。
def extract_complete_15_candidates_electoral():
# ...
# 15名の候補者と政党を、先に「正解リスト」として定義してしまう
all_candidates = [
'江原 くみ子', '津村 大作', '伊藤 岳', '矢倉 かつお', '武藤 かず子',
'増山 ゆうか', '高井 たまき', '山田 信一', '桜井 ななえ', 'くまがい 裕人',
'りゅうの まゆみ', '古川 俊治', '大津 力', '斉藤 よしひで', '石濱 哲信'
]
all_parties = [
'国民民主党(新)', '日本改革党(新)', '日本共産党(現)', '公明党(現)', 'チームみらい(新)',
'日本誠心会(新)', '社会民主党(新)', 'NHK党(新)', 'れいわ新選組(新)', '立憲民主党(現)',
'日本維新の会(新)', '自由民主党(現)', '参政党(新)', '無所属(新)', '日本保守党(新)'
]
# ...このように、処理したい候補者と政党の全リストを、あらかじめPythonのリストとしてハードコード(直接記述)してしまいます。これが後々の処理の「答え」として機能します。
Step 2: 表を2つに分けて、ピンポイントで情報を抜き出す
次に、データが2つの表に分かれている問題に対処します。これも、それぞれの表がシートのどのあたりにあるか、行番号を直接指定して処理を分けてしまいます。
# ...
vertical_data = [] # 最終的に縦長データを入れるための空のリスト
# 第1セクション: 最初の10名(行14~121あたりをループ)
for i in range(14, 121):
row = df.iloc[i]
# 市区町村名が書かれている行を見つける
if is_municipality_row(row):
municipality = str(row.iloc[1]).strip()
# 10名の候補者の列をループ
for j in range(10):
votes = row.iloc[3 + j] # 得票数のセル
# 縦長データを作成してリストに追加
vertical_data.append({
'市区町村名': municipality,
'候補者名': all_candidates[j], # 正解リストから名前を取得
'党派名等': all_parties[j], # 正解リストから党派を取得
'得票数': int(votes)
})
# 第2セクション: 残りの5名(行167~275あたりをループ)
for i in range(167, 275):
# ... 同じように処理 ...
for j in range(5):
# ...
vertical_data.append({
'市区町村名': municipality,
'候補者名': all_candidates[10 + j], # 正解リストの11番目から
'党派名等': all_parties[10 + j], # 正解リストの11番目から
'得票数': int(votes)
})
# 最後にリストをDataFrameに変換
result_df = pd.DataFrame(vertical_data)やっていることは、
- 市区町村の行を見つける。
- その行の各候補者の得票数セルを順番に見ていく。
- 得票数を見つけたら、「行から市区町村名」を、「列の位置と正解リストから候補者名と党派名」を取得して、新しい1行分のデータを作成する。
という、地道ですが確実な方法です。pandasの便利な関数一発!とはいきませんが、こうした泥臭い処理が、複雑なデータを制覇する鍵となります。
ここまでを掴んでしまえば、同じフォーマットで情報が交際された場合は、該当する箇所を変更するだけでほかへの応用が効きます。
Step 3: もう一つのデータも整形しよう!〜開票結果サマリー〜
さて、このスクリプトはもう一つ、「市区町村別開票結果調べ」というシートも処理しています。こちらも見ていきましょう。
市区町村等,得票総数,按分切捨票,有効投票数,無効投票数,無効投票率,投票総数,不受理,持帰り,その他,投票者総数,確定時刻,
,(A),(B),(A+B)(C),(D),(D÷E)%,(C+D)(E),(F),(G),(H),(E+F+G+...
県 計,3485290.0,0.0,3485290.0,129400.0,3.58,3614690.0,0.0,0.0,0.0,3614690.0,1.0,54.0
さいたま市西区,42803.0,0.0,42803.0,1572.0,3.54,44375.0,0.0,0.0,0.0,44375.0,21.0,45.0
...こちらは候補者別のデータほど複雑ではありませんが、ヘッダーが (A) や (B) といった記号で書かれていて、このままでは何を表すのか分かりにくいですね。そこで、この記号を分かりやすい日本語の列名に変換する処理を行います。
def transform_election_results_to_vertical(df):
# ...
# ヘッダー行を特定する('(A)'などのキーワードで探す)
# ...
# 選挙結果データの列名マッピング辞書
header_mapping = {
'(A)': '有効投票総数',
'(B)': '按分票数',
'(A+B)(C)': '有効投票数_計',
'(D)': '無効投票数',
'(D÷E)%': '無効投票率_パーセント',
# ... 以下続く
}
# ...
# マッピング辞書を使って、記号のヘッダーを日本語に置き換えていく
# ...ここでのポイントは header_mapping という辞書です。'(A)' というキーに対して '有効投票総数' という値を設定しておくことで、元の分かりにくい列名を、意味の通る列名に一括で変換できます。
ただデータを整形するだけでなく、こうして後から見ても分かりやすいデータに加工する一手間が、分析の効率を大きく左右します。
まとめ
今回は、分析の障害となる「横長データ」を、集計しやすい「縦長データ」へ変形させる、より実践的なデータクレンジングを見てきました。
- 複雑なデータは、まず理想の形(ゴール)をイメージする。
- 正解が分かっている情報は、先にリストとして定義してしまう。
- 決まったフォーマットなら、行番号や列番号を直接指定して処理するのも有効な手段。
- 記号的な列名は、辞書を使って分かりやすい名前に変換する。
特に、候補者のように項目が固定されているデータを扱う場合、今回のように「正解リスト」を作ってから処理するアプローチは、非常に堅牢で応用が効くテクニックだと思います。





